
可読性を確保するために重要なことの1つとして変数名があります。
とにかく分かりやすい変数名にしないとコードを書いてるときは何の変数か分かったとしても、後で見返したり他人がコードを読んだときに理解することが難しくなってしまいます。
かといって分かりやすく長ったらしい変数名にしてしまうと馬鹿っぽいくてダサいし処理にも何か悪影響があるのではないかと思ってしまいます。Webサイトで使うJavaScriptであれば、短い変数名にすればその分ファイルサイズが減ることになるので速度に影響あるでしょうが、ローカル環境だと関係あるのかどうかが不明です。
その辺をはっきりさせるべく簡単に検証してみることにしました。
検証方法はfor文内で「1文字」「10文字」「26文字」「79文字」の変数に0を代入するコードをそれぞれ20行記述したうえで、100万回ループする処理を1万回実行して処理時間の最大値・最小値・平均値・中央値を計測しました。
また、全ての計測時間をヒストグラムにすることで視覚的にデータを見れるようにしています。
ちなみに「26文字」は全アルファベットの文字数で、「79文字」はPythonのコーディング規約であるPEP8で定められている1行に書ける文字数の制限値です。文字列はアルファベットをa~zまで必要文字数に達するまで繰り返してるだけの単純なものに設定しました。
検証結果
| 1文字 | 10文字 | 26文字 | 79文字 | |
| 最大値 | 1.73163779999595 | 1.34376320010051 | 0.839303499902598 | 1.3408202000428 |
| 最小値 | 0.697956399992108 | 0.627431500004604 | 0.51520799996797 | 0.648974699899554 |
| 平均値 | 0.805019046840095 | 0.676074002980068 | 0.566312443770422 | 0.731870613979839 |
| 中央値 | 0.797681350028142 | 0.6679255500203 | 0.559355200035498 | 0.725057400006335 |
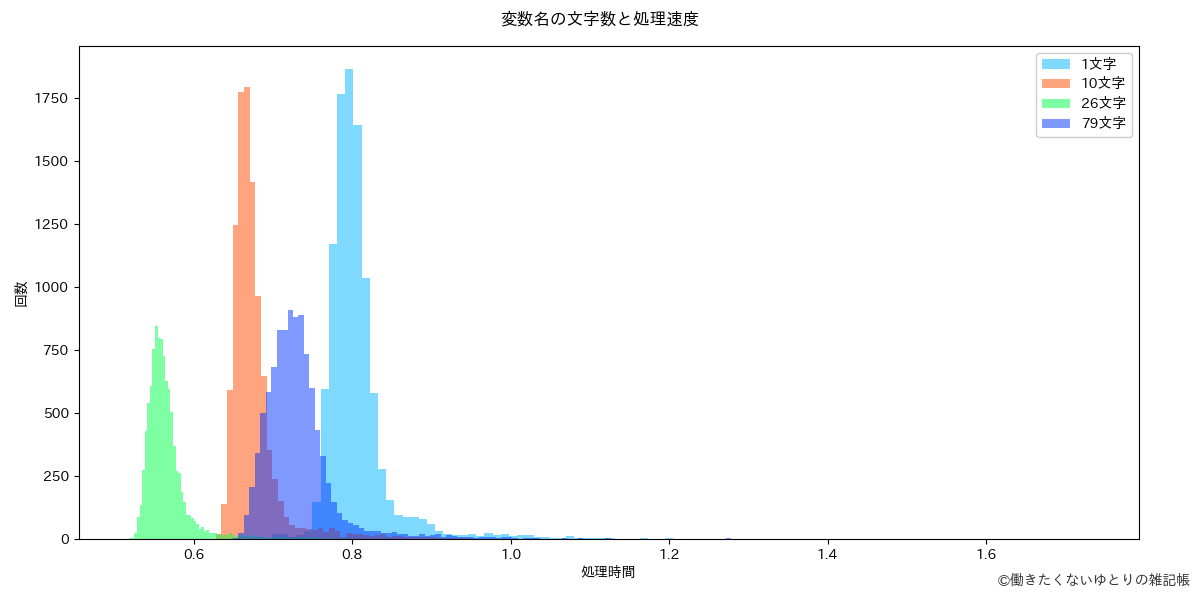
データをご覧の通り何ともいえない結果になっています。
「26文字」<「10文字」<「79文字」<「1文字」の順でまさかの「1文字」が1番遅い、というか文字数と順位がバラバラです。「76文字」が中間に位置しているのも意味不明ですし、個人的には想定外な計測結果でした。
実はこの検証結果は2回目のデータなんですよ。1回目は変数を10行で計測したら「1文字」<「10文字」<「26文字」で順当かと思いきや、そのときも「76文字」が他の文字数と重なる位置にあったため計測ミスを疑って20行に増やしたところこうなりました。
私の知識では何故こんな計測データになったのか分からないのでAIに聞いてみたところ、どうやらPythonは変数名をハッシュテーブルで管理しているらしく、どの文字数でも一定のハッシュに変換されるとのこと。だからその時のハッシュの計算周りで差が発生しているのかも…?みたいな返答でした。(本当かは不明です)他にもI/Oとかメモリとかいくつか提案されたけどこれが無難な推測だと思います。
本当はもっとぶん回して検証したかったのですが私の限界環境ではこれ以上の計測は無理なので諦めました。
いずれにしれも変数名の文字数は処理速度に関係ないというか気にしなくていいのかもしれません。なので如何にしてスマートな変数名を名付けるかだけを考えれば良さそうです。
コメント